Meccanica cerebrale
Avanzamento degli studi
|
|
Meccanica cerebrale
Avanzamento degli studi |
Bilingue - Bilingual
![]() -
-
![]()
11 luglio 2009
1. I comandi chain ed execute del PASCAL non
funzionano sul mio computer, per cui occorre lanciare manualmente
alcuni programmi. Sarebbe bene usare una versione più moderna
di PASCAL.
2. Ho due computer su uno, quello più
nuovo, TABULA4 è lentissimo richiede 10-15 minuti, su quello
più vecchio meno di 1 secondo!
3.Forme semplici
tipo I o L portano nel programma RICON a valori numerici di potenza
che eccedono i massimi ammessi dal tipo di variabile usata (ho usato
il tipo Byte per risparmiare memoria). Non è un errore
concettuale ma il programma va riscritto.
4.Quando si tratta di elaborare molte forme in successione il programma RICON funziona male. Ad esempio se elaboro due E quando il file RICORDI è vuoto il programma funziona in modo corretto e si hanno i collegamenti giusti fra le caratteristiche delle due forme. Se RICORDI contiene molte forme, il riconoscimento richiede l'applicazione ripetuta di RICON e le stesse due E dell'esempio precedente vengono elaborate male nel senso che il programma non collega più bene le loro caratteristiche! E' un errore grave, perché limita il numero di forme da elaborare, ma è un problema tecnico non concettuale a cui forse si rimedia usando una versione più moderna di PASCAL. Per rendersi conto che concettualmente i programmi funzionano provate, con il file RICORDI vuoto a elaborare una A, poi una R, poi ancora un'altra R. Essa sarà riconosciuta già da RICON. Il riconoscimento sarà migliorato da UNIRES e DELTA. Per questo lanciate T1. Ora cancellate RICORDI e elaborate molte forme ma non A o R. Fatto questo rifate la memorizzazione della e delle R come fatto prima: vedrete che i valori e i collegamenti sono tutti diversi e sbagliati. Io non ho la capacità di rimediare a questi difetti.
5.Il programma DELTA cerca le differenze fra le immagini, i suoi risultati vanno collocati in un contesto sintattico. Per ora ho usato una valutazione dei suoi risultati non è concettualmente corretta, l'ho usata solo perché spesso funziona.
17 luglio 2009
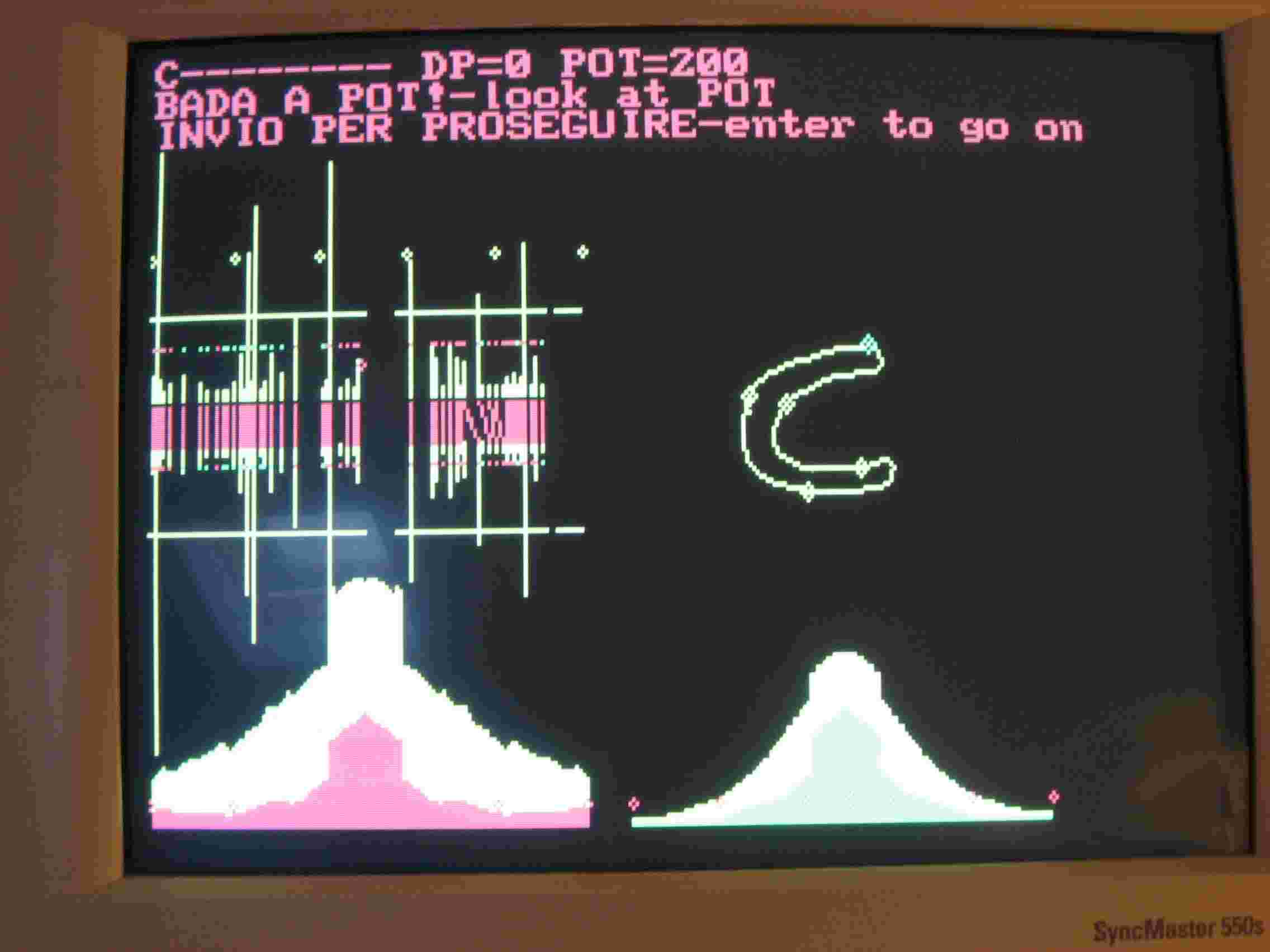
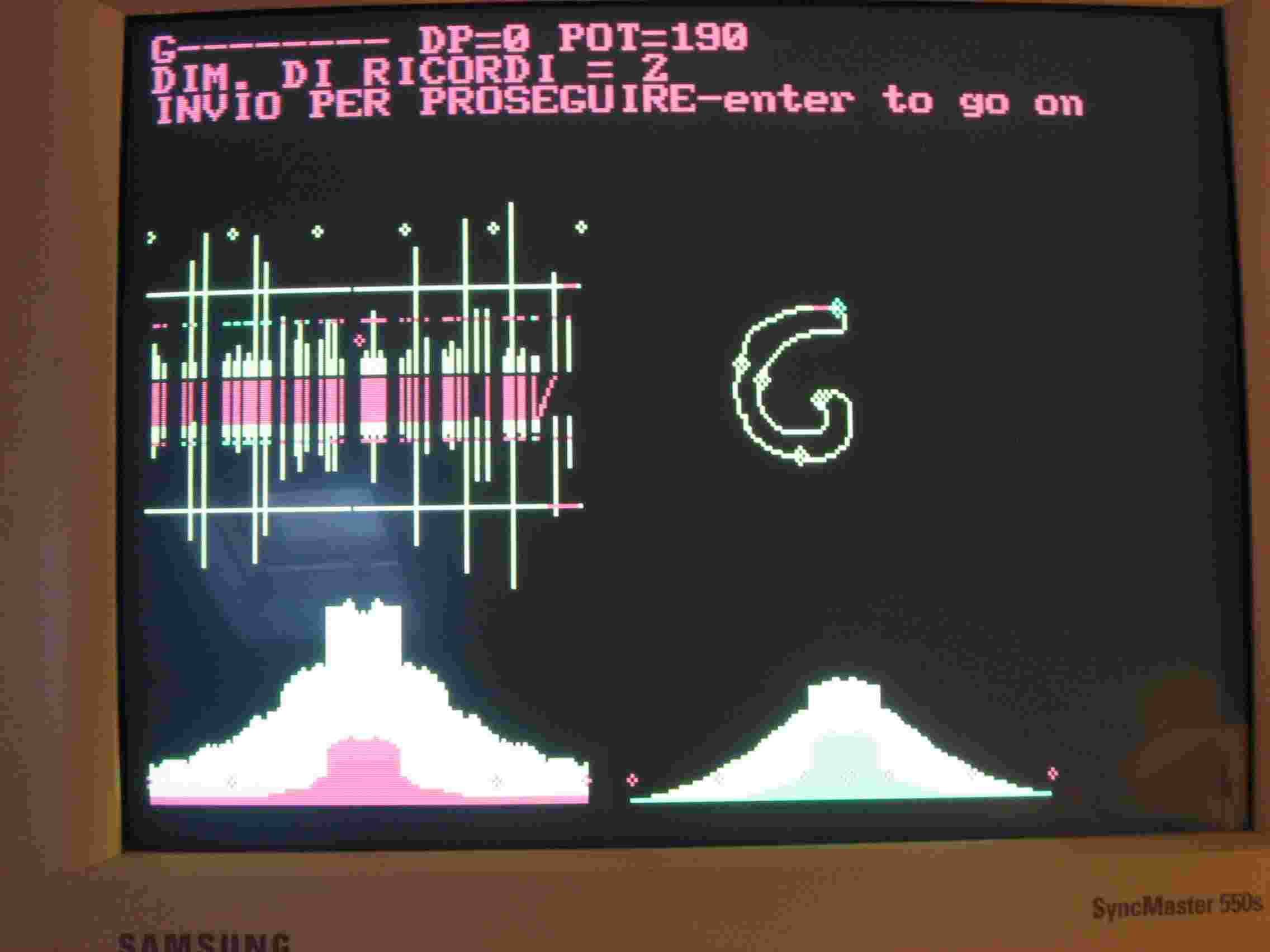
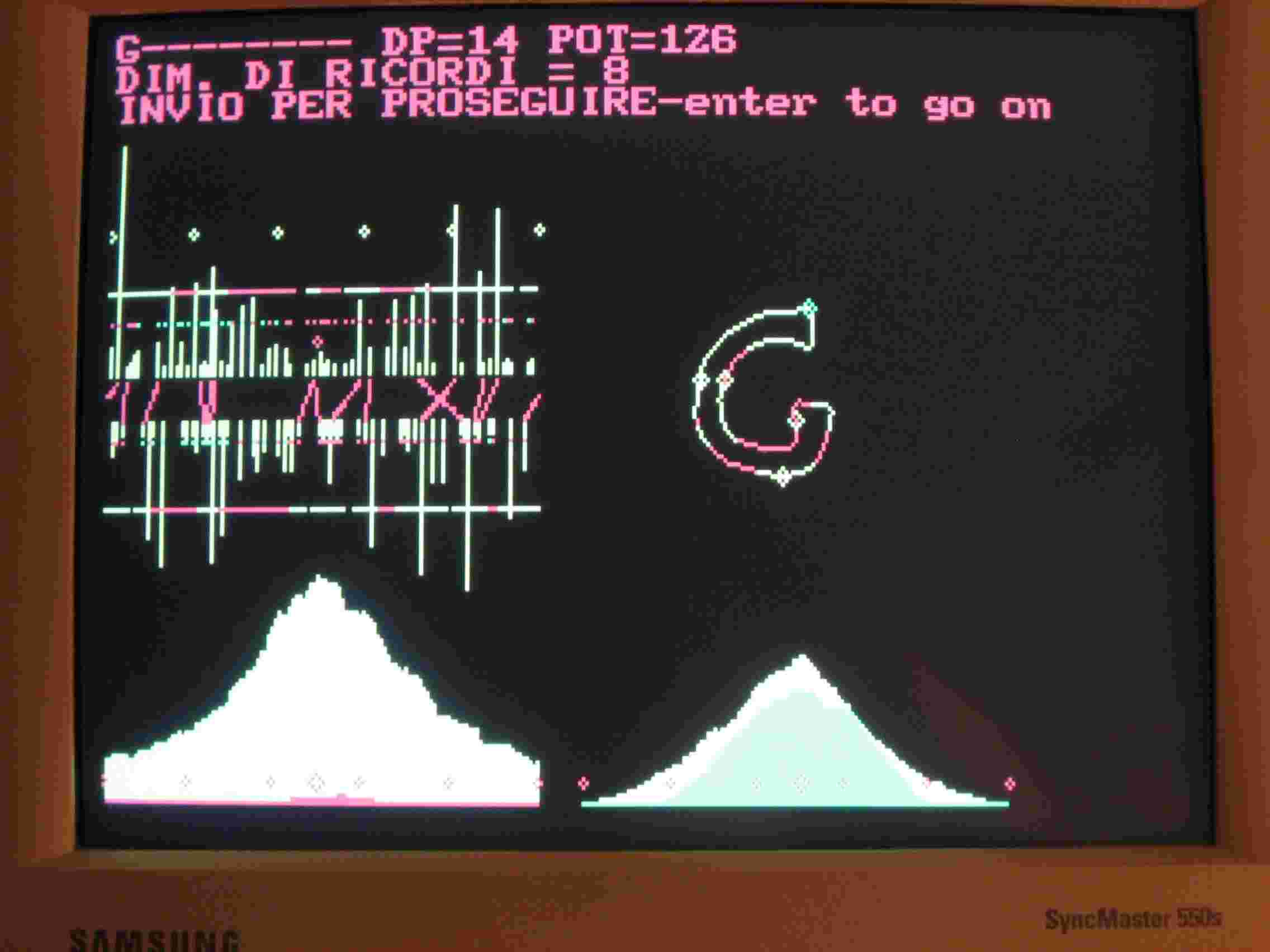
Il funzionamento di RICON va migliorato, anche se quando vi sono poche forme in memoria funziona adeguatamente. Quando vi sono molte forme smette di funzionare ma ripeto è un problema tecnico, non concettuale. Ho inserito in memoria, nel file RICORDI due forme C11 e G11, le potete vedere in fig.1 e fig. 2.
|
|
Poi ho rilanciato il programma con le stesse due figure memorizzate. Osservate la Fig.1, vi è una linea di 6 asterischi in alto, ogni tratto fra due asterischi corrisponde a 50 pixels del contorno della figura. Il primo asterisco a sinistra della linea corrisponde a quello verde in alto sulla C, il secondo al secondo sulla figura in senso destrorso. I perimetri di tutte le figure sono normalizzati a 250 pixels. Le linee gialle verticali sono le caratteristiche delle due C ed ovviamente sono speculari. In rosso i collegamenti fra queste caratteristiche. Dovrebbero essere verticali e lo sono tranne nella zona fra il IV e il V asterisco. E' un difetto di RICON. In Fig.2 lo stesso difetto lo fa fra il V e il VI asterisco. Un programma scritto con più accuratezza rimedia a questi errori che comunque non sono gravi, il programma MISCHIA li elimina. La procedura T.bat va comunque bene. Ecco che cosa capita quando lancio una G di foggia tipografica diversa da quella inserita.
|
|
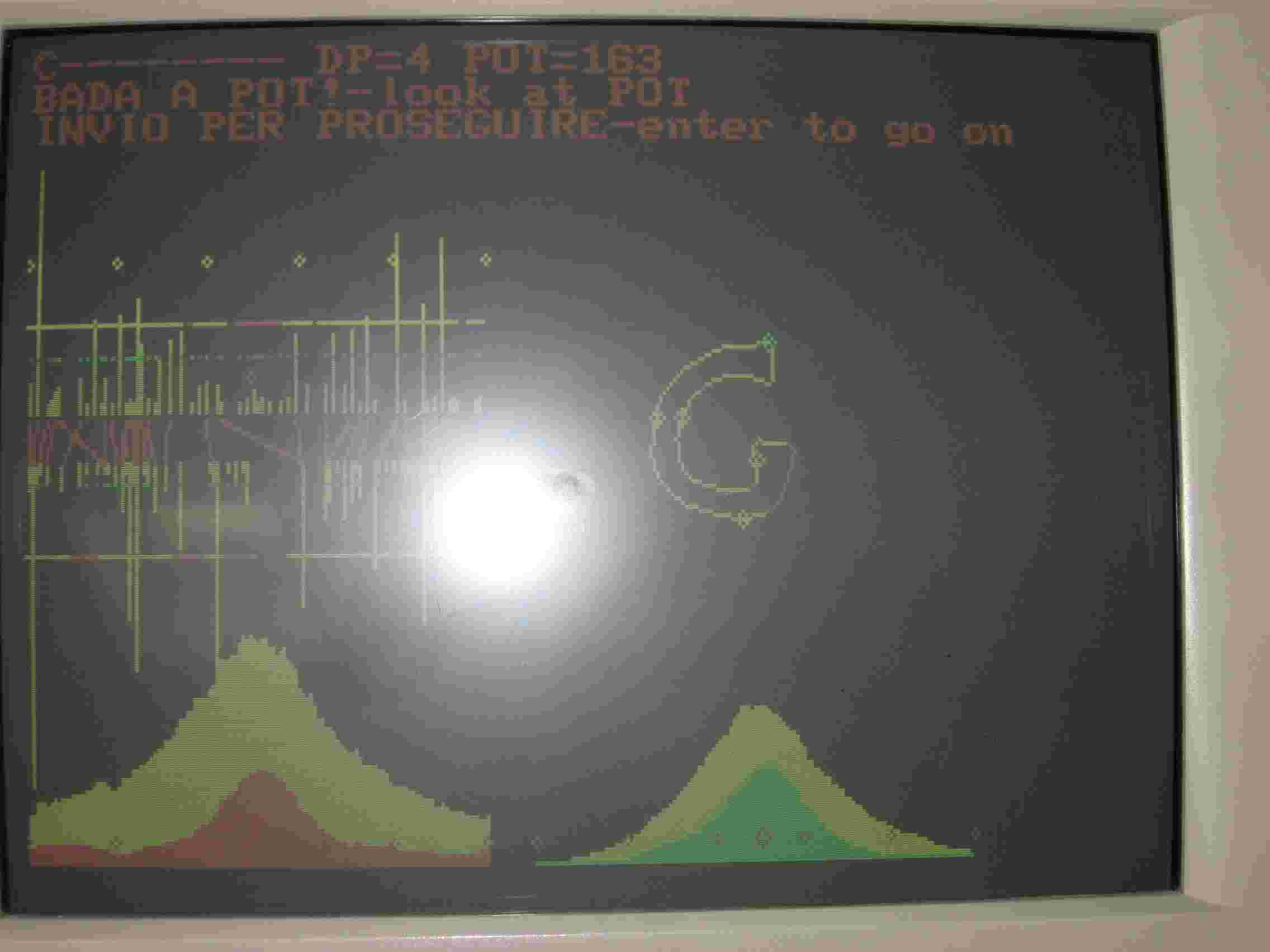
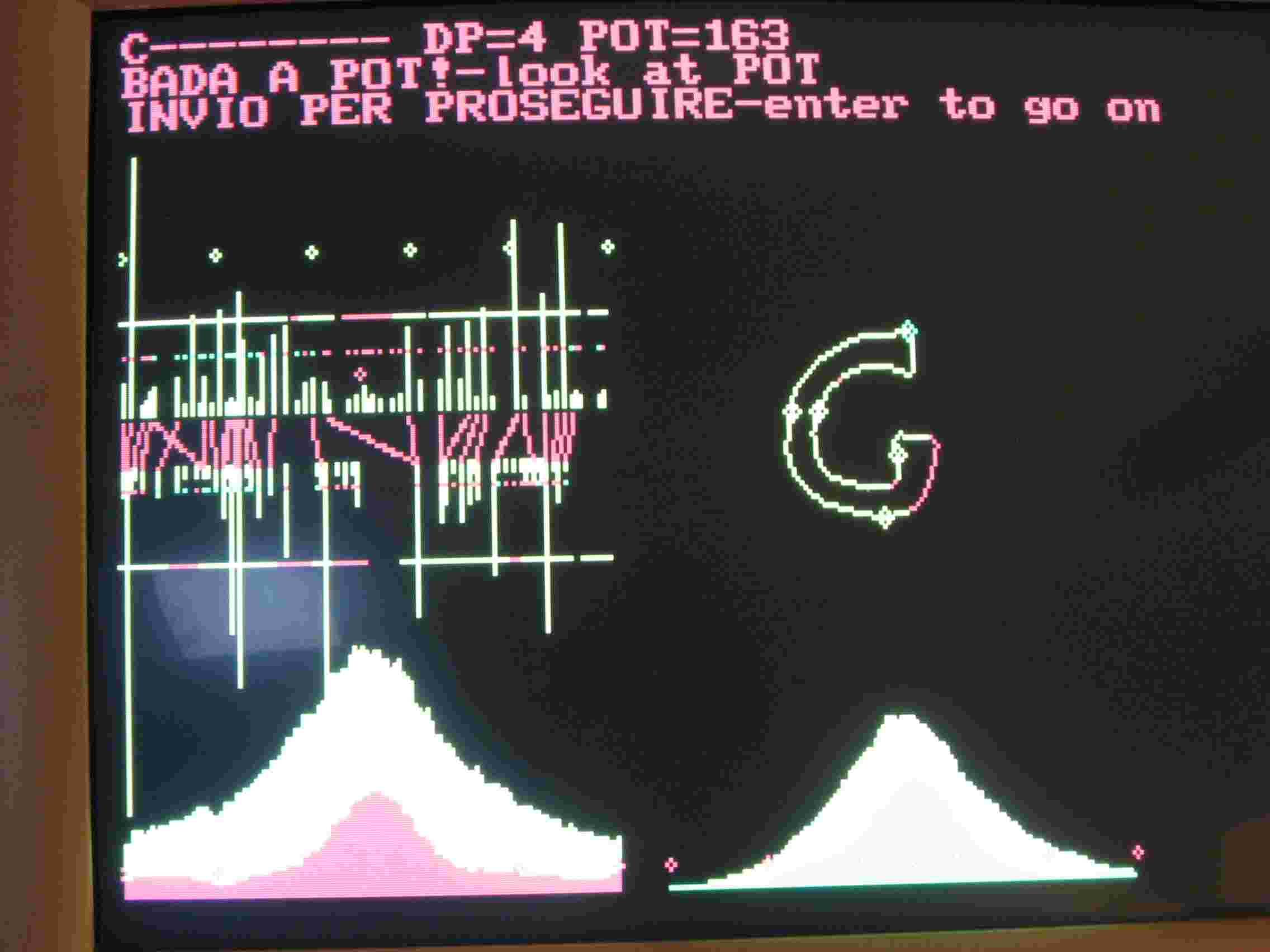
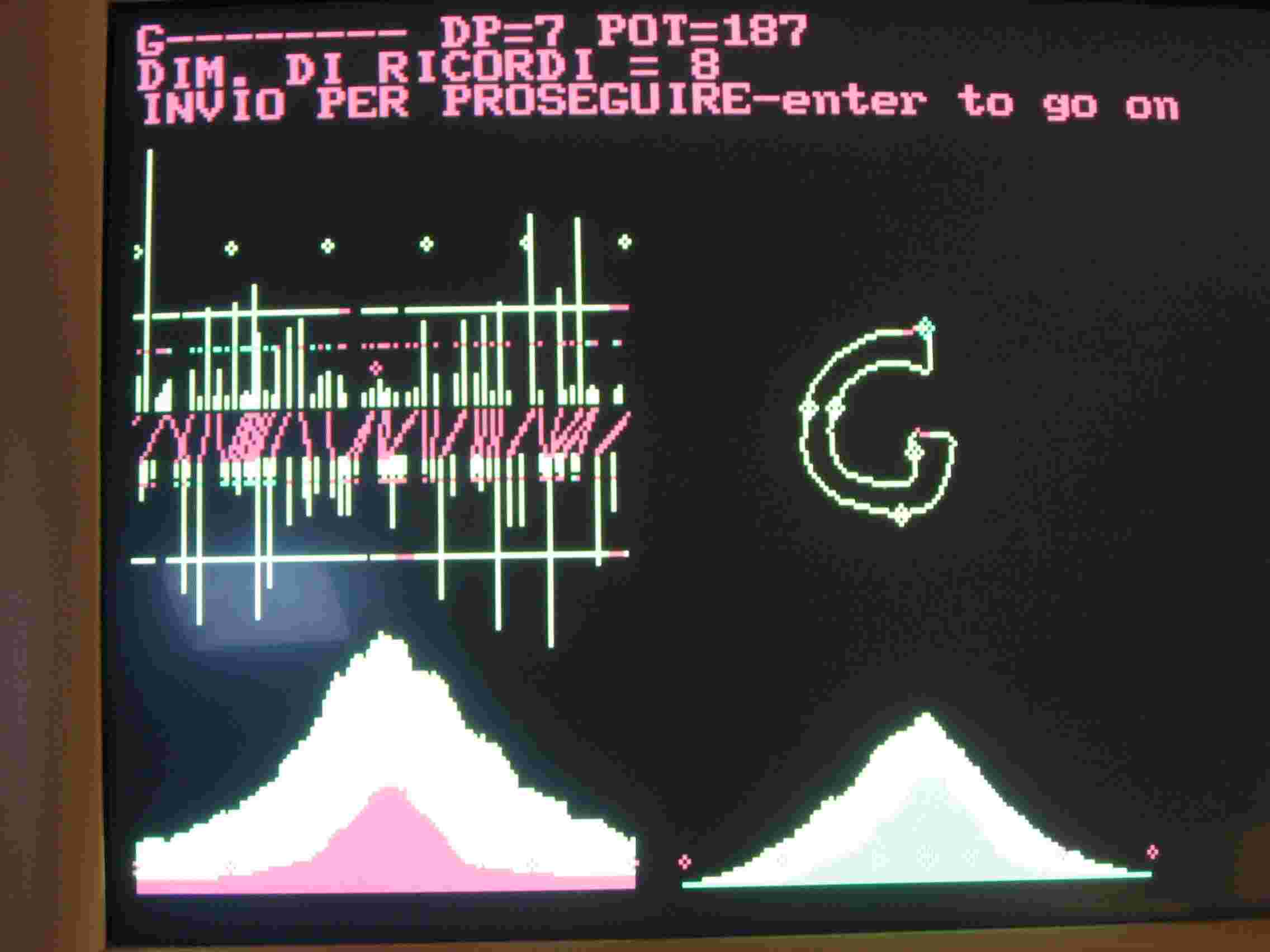
Il confronto con la C memorizzata da luogo ad una potenza di 163 (fig.3), e la macchina nota che la differenza fra la C memorizzata e la G presentata sta in basso a destra della G e segna la zona in rosso. Il confronto fra la G memorizzata e quella presentata da luogo ad una potenza di 197 (200 è il massimo, fig 4) e non trova particolari differenti. Le conclusioni del riconoscimento topologico sono nella seguente fig.5
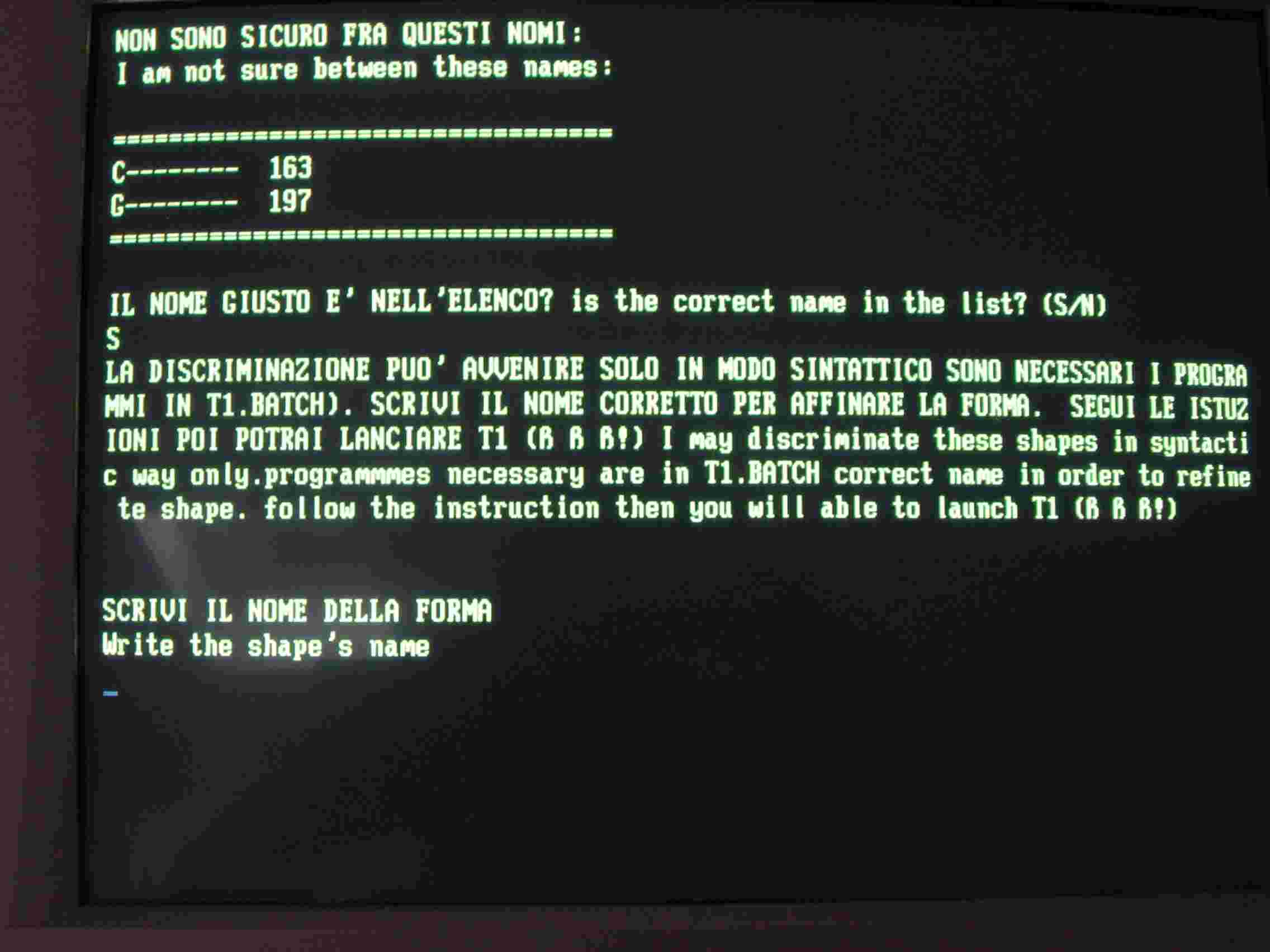
In effetti fra la C e la G la differenza è poca occorre il riconoscimento sintattico, che individui la differenza e in base a questa permetta la discriminazione. I programmi UNIRES e DELTA individuano la differenza ma i loro risultati andrebbero valutati nel contesto di una frase. Tuttavia ho realizzato un piccolo e scadente sistema di riconoscimento entro il programma DELTA, esso porta alle conclusioni della seguente fig. 6.
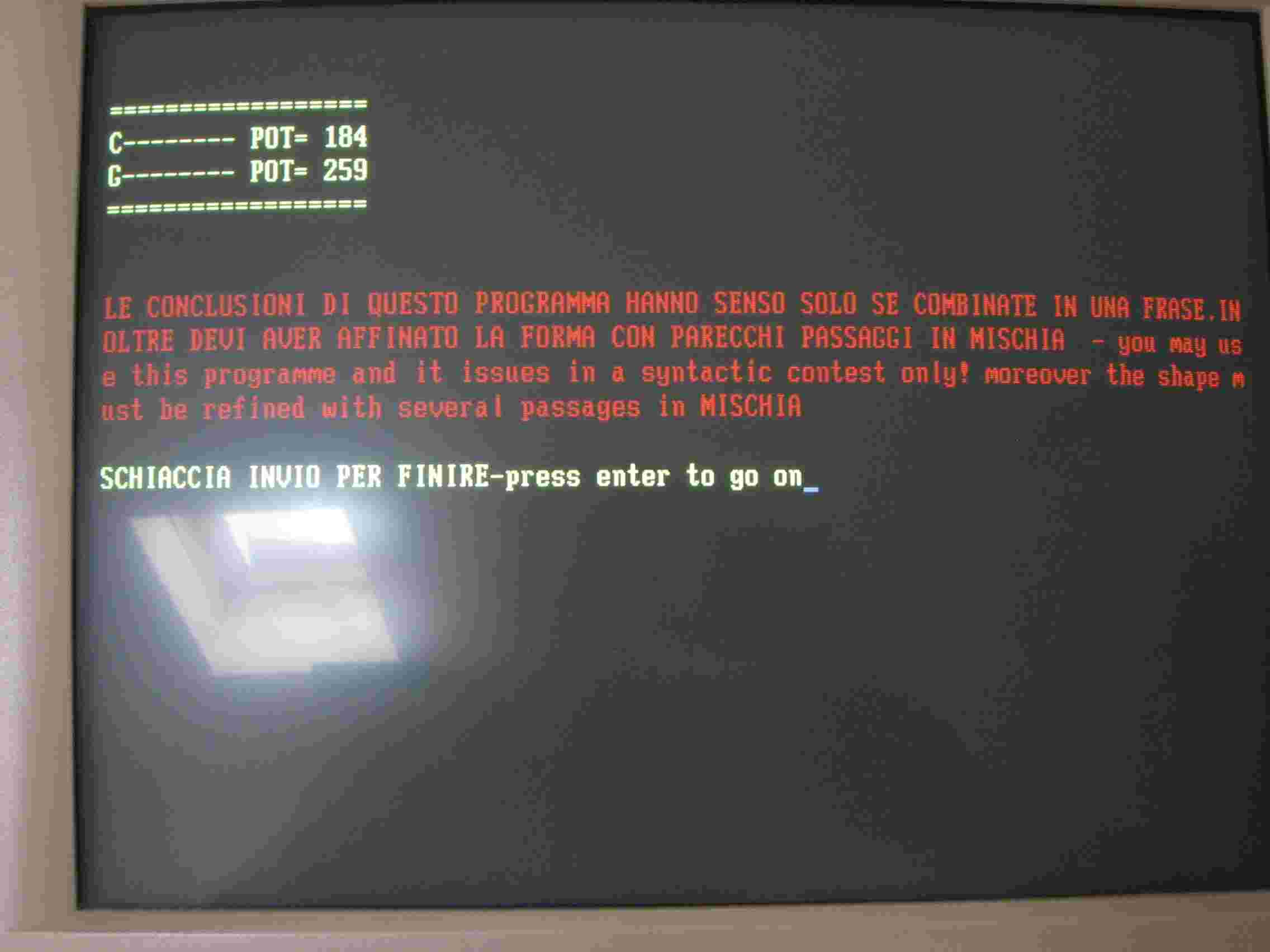
La potenza della C risulta 184 e quella della G, 259. Prima era pot. C= 167 e pot.G=197. La differenza fra la due potenze è di 34 nel primo caso e di 75 nel secondo. Da un punto di vista percentuale la differenza è del 20% nel primo caso e del 40% nel secondo. Migliora la discriminazione, anche senza usare la frase.
C e G vengono distinte correttamente. E' ovvio io mostrassi al sistema, che ha in memoria C e G forme quali A, P o Z i collegamenti con le lettere memorizzate sarebbero scarsi come la potenza. Mentre se memorizzo A11 ed R11 poi mostro altre A ed altre R che sono simili, il sistema le riconosce. Idem per E ed F e questo avviene, in generale, senza affinare le lettere con il programma MISCHIA, con le lettere affinate il riconoscimento migliora.
Tutto bene dunque? Niente affatto.
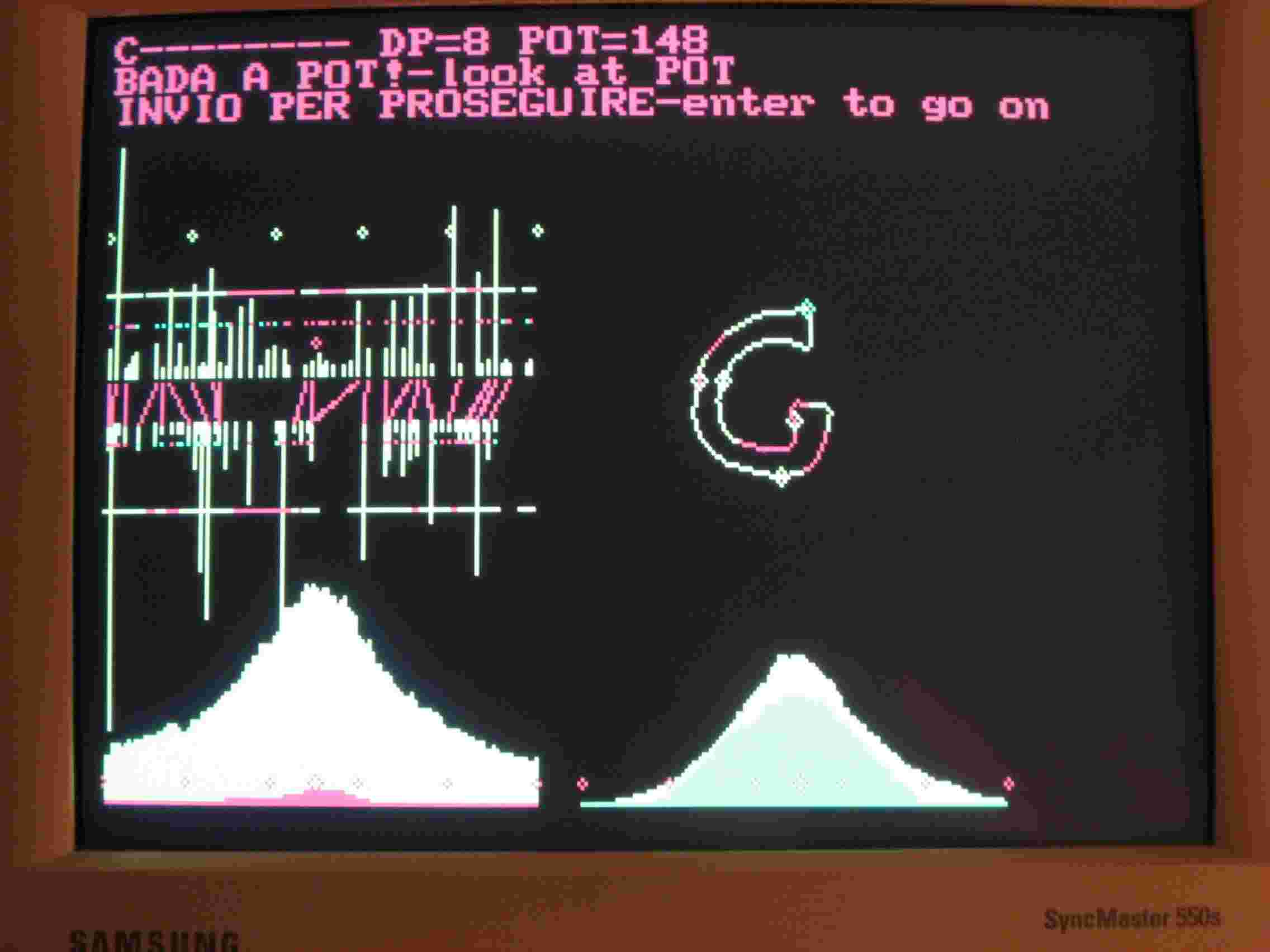
Se le lettere in memoria sono poche, due o tre, tutto funziona come previsto. Se le lettere in memoria sono 5 o 6 o di più, il programma smette di funzionare. Le stesse C11 e G11 memorizzate confrontate con la G21 non danno più i risultati delle Figg.3 e 4. Ecco il disastro che avviene con appena otto forme.
|
|
La differenza fra Fig.3 e Fig.7 esiste e la differenza fra Fig. 4 e Fig.8 è enorme. La Fig. 8 mostra eloquentemente il problema. Le caratteristiche della forma memorizzata, le linee verticali gialle sotto le linee rosse, non vengono collegate correttamente con le linee verticali gialle sopra, che rappresentano le caratteristiche della forma presentata, nel caso G21. Io non capisco perché succeda questo guaio. E' la stessa procedura che reiterata, 2 o 3 volte va, 6 o 7 no! Va detto che non sono un esperto di computer né un programmatore. Capisco che il problema viene dal nocciolo del programma RICON, quello che collega le caratteristiche delle forme: il Pascal non sopporta la sua reiterazione. Devo rimediare, forse è una questione di differenze di velocità di elaborazione entro il computer. Al limite proverò a usare un Pascal più moderno, ho il Borland Pascal 7, ma riscrivere RICON è penoso e penso che un competente possa risolvere il problema subito. Inoltre il Borland Pascal 7 è moderno per modo di dire, è del 1992.
20 luglio 2009
Ho trovato l'errore ed ho rimediato. Era nel programma RICON. Per normalizzare una variabile dovevo moltiplicarla, una sola volta, per il fattore 0,69. Siccome avevo messo questo fattore in una procedura che veniva reiterata, la variabile veniva moltiplicata ogni volta per 0,69, diventava sempre più piccola e scombinava tutto. Ora procederò a correggere UNIRES e DELTA, che potete provare fin d'ora. Badate a non considerare i risultati di DELTA, essi hanno senso solo in un quadro di riconoscimento sintattico. In Fig.9 e 10 vedete i risultati. In Fig.10, come in Fig.8 e in Fig.2 si vede la “Dimensione di RICORDI” ovvero il numero delle forma memorizzate. Stavolta con 8 forme i risultati sono quasi uguali a quelli di fig.2, dove le forme sono 2. Sul “quasi uguali” ci sarebbe molto da discutere....
|
|
In Fig. 9 vedete i risultati del riconoscimento topologico, che di basa sul solo contorno esterno. Le forme erano 8 in RICORDI ma 2 vengono escluse, la B e la D, perché pochissimo somiglianti con la G. Vedete che fra tutte la lettera C è quella che ha potenza maggiore. Infatti il programma RICON meccanizza la somiglianza “human like”. Chiede a un bambino quale fra le 8 lettere assomiglia di più alla G, dirà la C, di certo.
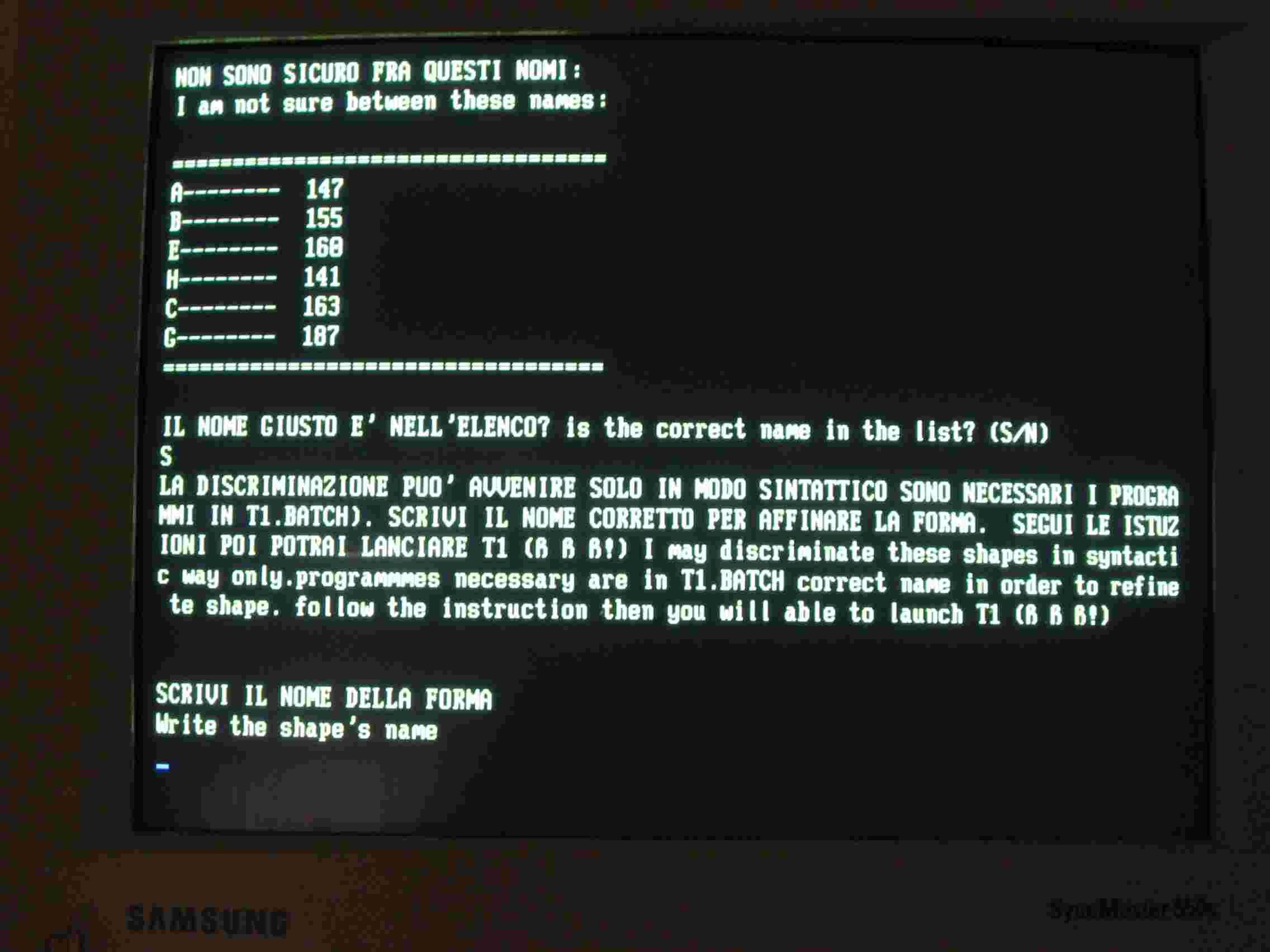
Fig.9
Ora procederò a correggere UNIRES e DELTA, che potete provare fin d'ora. Badate a non considerare i risultati di DELTA, essi hanno senso solo in un quadro di riconoscimento sintattico.
1 agosto 2009
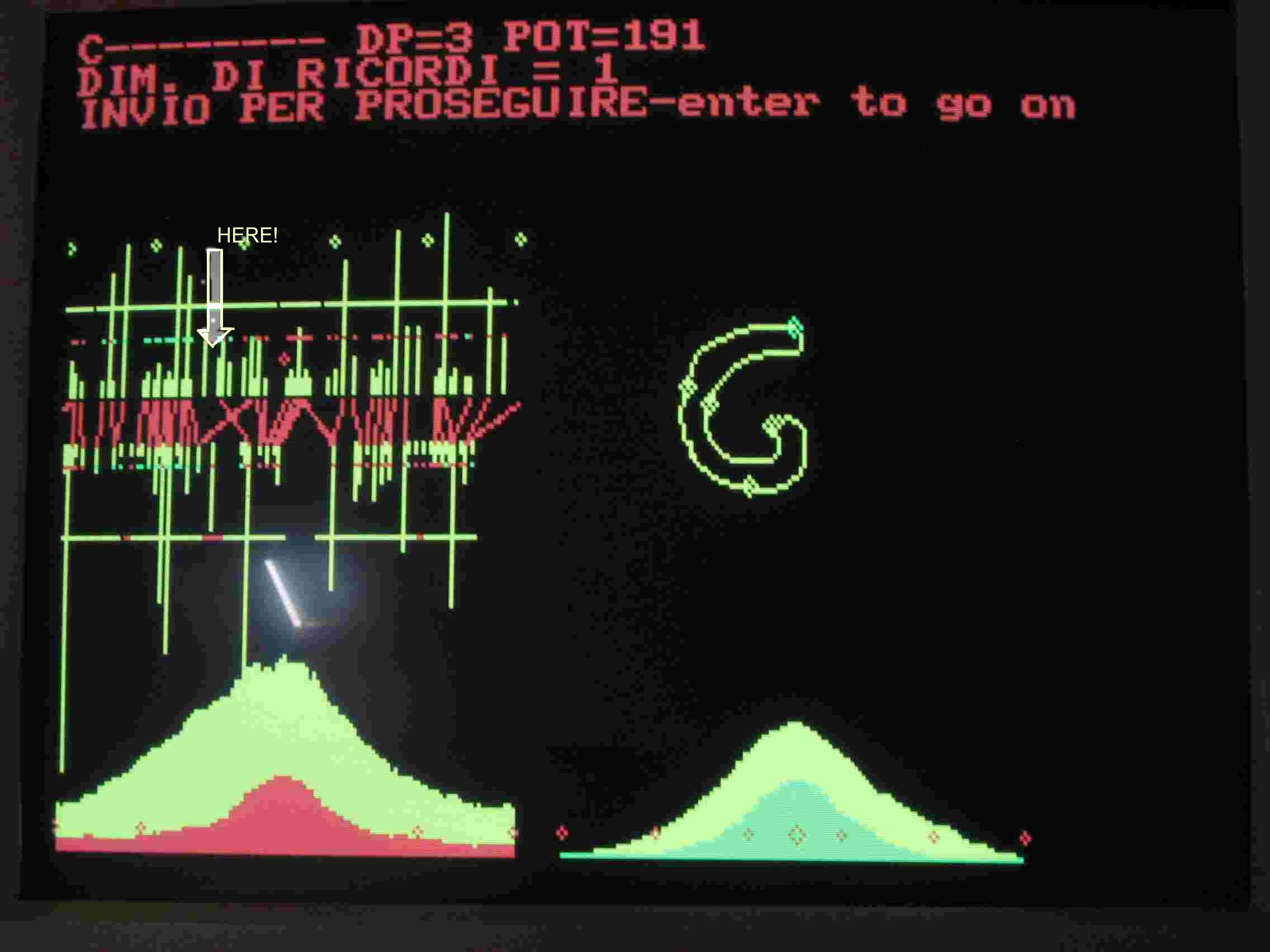
Concettualmente il programma MISCHIA funziona esso affina le forme e ne coglie l'essenza. Scusate questo modo di parlare volgare e osceno. In effetti almeno la parola essenza dovrebbe essere evitata in ogni discorso che abbia un minimo di pretese di ragionevolezza. Comunque si osservi la Fig. 10 in essi sono confrontati G11 su C11. In Fig. 11sono stati mischiati C11 con C12 e G11 con G12.
|
|
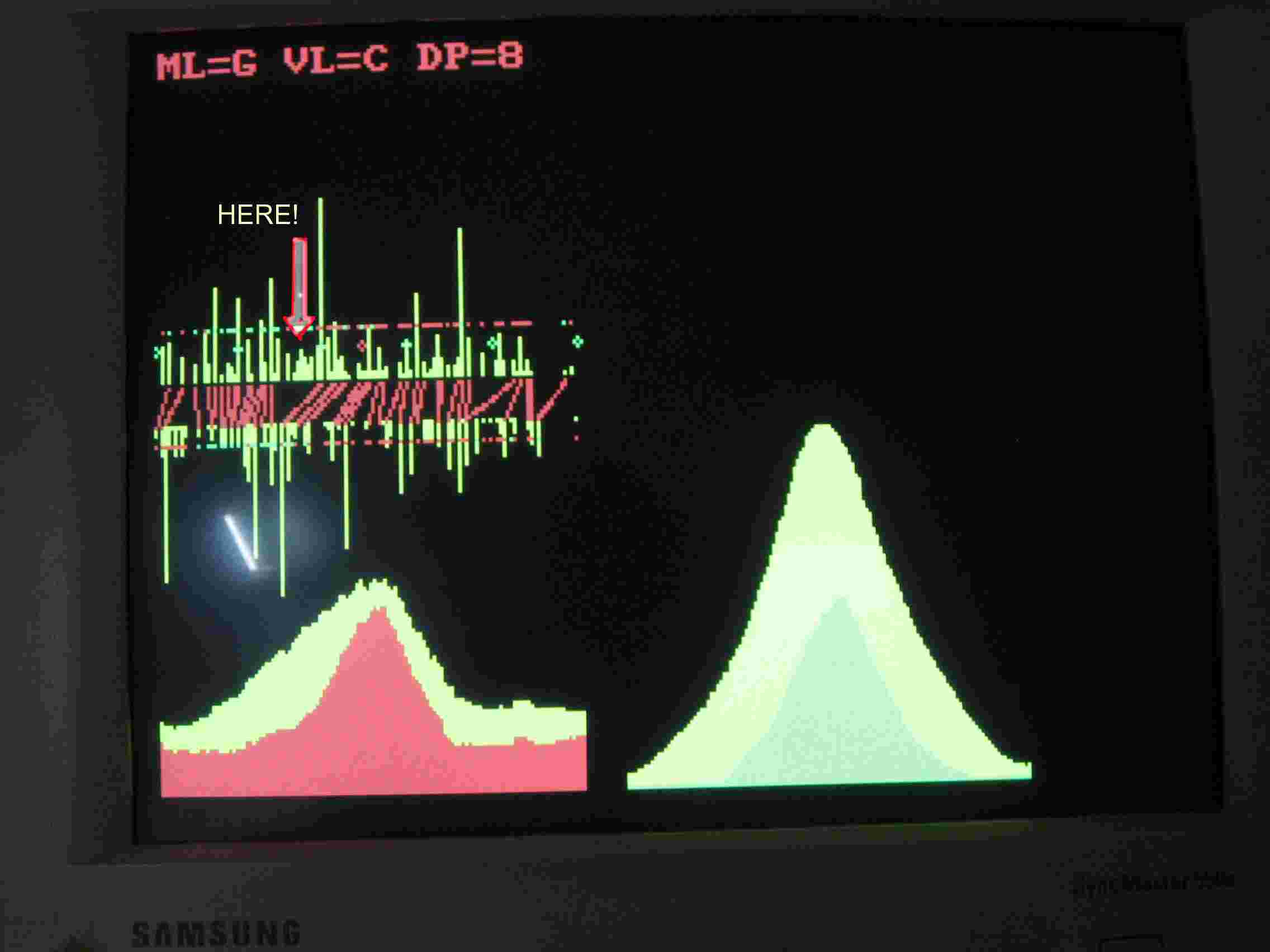
Anche un bambino capisce che la differenza fra la C e la G è nell'asticciola piegata in Fig.12.
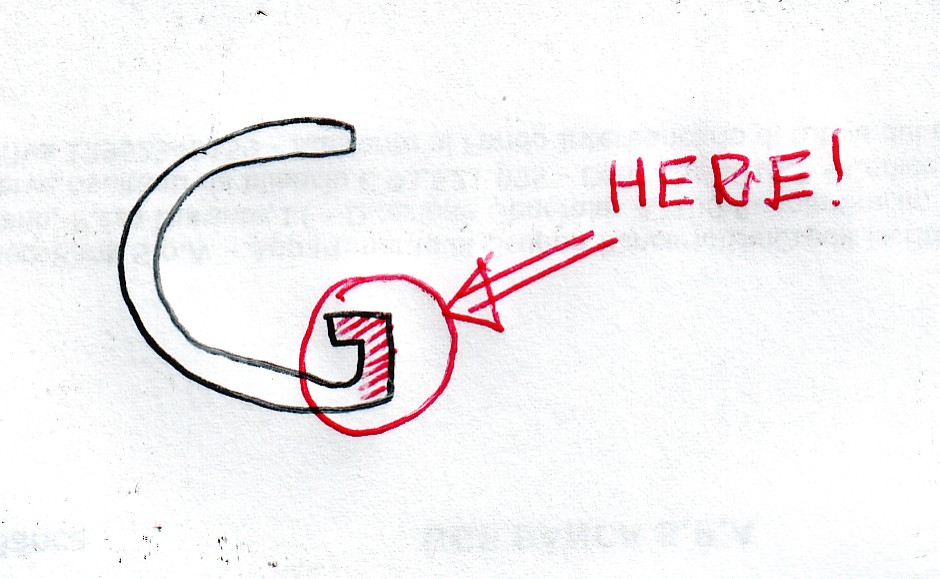
Fig.12
Nelle Figg.10 e 11 la zona è indicata dalla freccia e dalla parola HERE! In Fig.10 si nota la mancanza di collegamenti nelle colonne verticali superiori, quelle che rappresentano le caratteristiche della G11 ma anche in quelle inferiori, che rappresentano le caratteristiche della C11 memorizzata. Queste ultime caratteristiche dovrebbero essere collegate. Inoltre c'è un incrocio delle linee rosse, che collegano le caratteristiche: Questo è un errore che deriva da un errore nel programma RICON. Lasciando perdere l'ultimo errore si vede che in Fig.11 le cose vanno come si deve. Mescolando le caratteristiche di due C e di due G il programma UNIRES individua la differenza. Mescolando tre C e tre G la forma essenziale (sic!) delle due figure dovrebbe diventare ancora meglio definita e migliorare ulteriormente ad ogni aggiunta di lettere. UNIRES avrebbe vita facile a individuare le differenze e le somiglianze fra le parti delle varie forme. Sfortunatamente il programma UNIRES, già mescolando tre forme, mi avverte che supero i limiti di un array. Ho creato array piccoli perché altrimenti vado oltre i limiti della memoria. Detto questo devo riprendere il programma MISCHIA e vedere se posso rimediare di lì. Lottare con il computer è la mia attività principale.
17 agosto 2009
Ho, prima modificato, poi riscritto il programma MISCHIA nell'ottica di diminuire la dimensione degli array. E' stata una pena persa perché ne derivava la perdita di informazione e quindi dei particolari che permettono la discriminazione delle forme simili, come C e G. Con questo lavoro, volevo evitare l'altra strada, ovvia, ampliare gli array di UNIRES (e di RICON) ed evitare un overflow di memoria. Inoltre questi programmi sono di grandi dimensioni e complessità e riscriverli usando allocazioni dinamiche di variabili non è uno scherzo. Tuttavia è l'unico modo di fare.
24 agosto 2009
Dopo un mese di prove rinuncio all'idea di restringere i risultati di MISCHIA. Quando tento di diminuire il peso di questi risultati, in ogni modo faccia, finisco per togliere i piccoli particolari della figura il che rende impossibile il seguente riconoscimento sintattico. Chi ha fatto le prove ha notato che la parola pesante intendo un file di oltre 170 byte. Sono dimensioni risibili in assoluto ma l'elaborazione dei dati è complessa e lunga, diventerebbe semplice e veloce con una macchina parallela, costruita ad hoc, come il cervello. Senza sognare tuttavia chi conosce meglio di me i computers potrebbe riscrivere i programmi in modo più moderno ed avere a disposizione più di 64 kbyte di memoria, che è il mio standard. Al momento non vedo altri rimedi che usare poco MISCHIA, due volte al massimo. Con questa scelta la precisione del riconoscimento è fortemente ridotta. Ricordo però che questa è una versione ß. Chi è interessato al lavoro badi agli aspetti concettuali.
20 settembre 2009
Ho eliminato alcuni difetti nel programma RICON, nel programma UNIRES e nel programma DELTA. Ho ottenuto un importante miglioramento del riconoscimento. Non è stato un mero lavoro di “debug”, senza apporti concettuali, gli studi “matti e disperatissimi” svolti nel mese di luglio e agosto, che non hanno risolto nulla per MISCHIA mi hanno portato a scoprire un nuovo modo di sogliatura delle caratteristiche che individua le differenze fra le immagini, che ho adottato nei tre programmi citati. Voglio rimarcare che il riconoscimento”quasi sintattico” di DELTA risulta potentissimo, anche senza l'uso del programma MISCHIA, che non riesco a far funzionare per i miei come programmatore. Mi sovviene che i contadini dicevano di certi animali: “gli manca solo la parola”: verissimo, l'aggiunta del linguaggio rende migliore il riconoscimento e quindi la capacità di previsione. DELTA com'è ora è solo la base su cui innestare il linguaggio.
21 settembre 2009
Il programma MISCHIA non va demonizzato, anzi funziona bene, non solo sotto il profilo concettuale e migliora notevolmente il riconoscimento. Per rendervi conto fate così: cancellate il file RICORDI dalla cartella dei programmi. Lanciate T.batch e memorizzate 2 lettere alfabetiche che si assomigliano, per esempio A1 e R1. Poi lanciate T.batch per una di esse, di foggia tipografica diversa, Per esempio R2. Da OPZIONI di certo uscirà che è impossibile discriminare senza la sintassi fra A e R. Lanciate T1.batch forse vi darà la risposta errata, per esempio A. Se però dopo OPZIONI lanciate MISCHIA e mescolate due A e due R il riconoscimento sarà inequivocabilmente corretto. L'ottimale sarebbe mescolare la forma riconosciuta con quelle già in memoria: le forme si affinerebbero bene. Comunque anche un modesto uso di MISCHIA, che è una rete neuronale, le percentuali di riconoscimento esatto sono manifestamente crescenti. La stessa cosa si può dire in esito al miserrimo uso della sintassi, effettuato con DELTA.
3 ottobre 2009
Il programma che richiedeva più spazio in memoria era UNIRES. Sono riuscito a scriverlo in modo che sia ugualmente efficiente ma meno ampio. Ora i risultati di MISCHIA fanno molti meno danni. Devo ancora rifinire MISCHIA e DELTA e poi potrò passare al sintattico.
5 ottobre 2009
La riscrittura di UNIRES comporta la riscrittura di MISCHIA. Mi sono accorto che esso nella versione attuale funziona malamente. Non usate MISCHIA fino a nuovo avviso.
6 dicembre 2009
Ho dovuto lavorare molto su MISCHIA. Dopo avere tentato inutilmente di affinarlo mi sono persuaso che occorrevano dei miglioramenti concettuali. Com'era MISCHIA prima, diminuiva la potenza degli elementi che si presentavano raramente e li annullava quando andavano sotto una soglia. Così facendo gli elementi poco potenti erano svantaggiati e finivano di essere eliminati. Quindi sparivano i particolari della figura che aiutavano a riconoscerla già nel modo sintattico. Allora ho pensato di introdurre l'idea di persistenza del singolo elemento, imponendo la sua cancellazione se dopo un certo numero di volte in cui si presentava la figura esso non era raramente presente. Siccome io dispongo di strumenti limitati ho imposto di cancellare quegli elementi della figura che si presentano 1 volta su tre volte che la figura è presentata. Anche operando in questo modo rozzo il riconoscimento è notevolmente migliorato. La modifica a MISCHIA ha comportato la correzione molti programmi. Correzione non ancora ultimata. Entro pochi giorni credo di potere pubblicare i programmi riveduti. Noto che è stato un lavoro che è durato due mesi.
11 dicembre 2009
Fatto. Ho anche trovato altri errori. Sostanzialmente i programmi funzionano ma andrebbero riscritti e raffinati soprattutto si dovrebbe usare un linguaggio di programmazione che permetta una memoria più ampia. Ora comunque comincerò a dedicarmi al riconoscimento sintattico.
8 gennaio 2010
Purtroppo quello che avevo scritto l'undici dicembre era troppo ottimistico. Ho passato questo mese a lavorare sul programma MISCHIA. Ho dovuto ridurlo e renderlo più rozzo perché nella sua versione primitiva è troppo pesante per il mio vecchio compilatore. Pubblico questa versione di MISCHIA che è insoddisfacente: si limita ad affinare la prima forma che gli si è presentata, facendole perdere i dettagli inessenziali ma non la arricchisce dei particolari che provengono da altre forme, mostrategli successivamente. Mi sono persino venuti dei dubbi sul funzionamento di MISCHIA nella versione completa: io sono un convinto sostenitore del metodo sperimentale e in questo caso il conforto dell'esperimento non c'è. Comunque è tutto quello che sono riuscito a concludere.
15 gennaio 2010
Ho cambiato parti del programma MISCHIA ed dl programma UNIRES, base del riconoscimento sintattico. Ho potuto notare un buon miglioramento dei risultati, questo mi permette di concludere che la teoria alla base di questi programmi è buona ma la loro scrittura è ben lungi da essere definitiva. Mi sovviene Galileo che diceva: “provando e riprovando”.
11 aprile 2010
In questi tre mesi ho eseguito debug ed ho anche iniziato a meccanizzare ciò che in termini usuali si può chiamare l'attenzione ovvero l'isolamento della parte più significativa della scena, che in questo caso è una parte della linea di contorno della figura. In assenza di dispositivi che colgano il movimento è molto difficile indirizzare l'attenzione, però entro modesti limiti ci sono riuscito e, con questa miglioria, il tutto funziona meglio. A volte l'algoritmo di estrazione dei contorni produce contorni interrotti: poco male, l'apprendimento richiede qualche figura con i contorni chiari poi con il sintattico basteranno pezzi di contorno. Anche per i bambini (sotto i tre anni) è così: guardate i loro pupazzi e le illustrazioni dei loro libri, sono fortemente contrastati, questo aiuta il loro sistema visivo a estrarre contorni completi, poi da grandi non è più necessario. Inoltre una retroazione in SCEGLI che modifichi la soglia di TABULA4 risolverebbe molti casi. Non mi sono impegnato in questo miglioramento perché lo giudico inessenziale nell'economia del lavoro. Ritengo invece accettabile la parte topologica. Funziona nei limiti previsti. Il riconoscimento delle forme in base ai loro angoli, a mio avviso, è provato. La confusione in cui cade il programma è quella in cui un bambino sotto i tre anni, che possa disporre del solo senso della vista e di fronte a forme semplici come quelle che si possono disegnare in un quadrato di 70x70 pixels. Chi vuole aggiunga forme, sperimenti e mi contatti. Il programma MISCHIA andrebbe rifatto ma non ho tempo, dovrei studiare troppe cose sui calcolatori. Idem per i programmi da TABULA(I) che simulano troppo rozzamente il modo umano per l'estrazione dei contorni. Ora comincerò a migliorare UNIRES e DELTA, che sono solo degli abbozzi e non vanno ancora usati.
15 giugno 2010
In questi due mesi ho continuato il debug e la riscrittura del riconoscimento protosintattico. Ho chiamato protosintattico questo riconoscimento perché sta alla base del riconoscimento sintattico e della formazione della frase. La discriminazione che produce è impressionante. Esso risolve quasi sempre le ambiguità che derivano dal riconoscimento topologico e indica il riconoscimento corretto senza possibilità di equivoci. Notate che si tratta di immagini di 70x70 pixels e che il riconoscimento non è ancora sintattico. Volendo si potrebbe ancora migliorare il programma MISCHIA, che è una rete neuronale, tuttavia anche se è rozzo fa pochi guai. Anzi proprio la modestia di tutto l'insieme dei programmi avvalora l'idea di fondo: gli angoli sono gli elementi essenziali per riconoscere le forme. Quest'estate non credo lavorerò molto meno sui programmi perché, a Dio piacendo, vorrei rispondere al libro di Richard Gregory “Occhio e cervello” mettendo in ordine le mie idee sulla visione. Chi vuole provare i programmi lanci T, che conduce ai risultati del riconoscimento topologico. Se il riconoscimento non è univoco scriva pure il nome della forma corretta ma poi può non lanciare MISCHIA, lanci invece T1 e veda i risultati. MISCHIA lo può lanciare dopo. Nulla osta però seguire il flusso del programma.
29 agosto 2010
In questi due mesi e mezzo mi sono preso una settimana di vacanza per il resto ho studiato. Mi ero riproposto la questione: “Come si formano nel nostro cervello le immagini del mondo che guardiamo”?. E' un problema annoso ma penso di essere arrivato alla sua soluzione, combinando Hume, Darwin, la neurofisiologia e le illusioni ottiche. Presto pubblicherò il lavoro. Sono su facebook.
23 settembre 2010
Ho pubblicato come, secondo me, si formano le immagini del mondo nel nostro cervello. Chi pensa che la visione sia la ripresa fotografica del mondo dovrebbe riflettere che essa è rovesciata sulla retina; poi, nella corteccia visiva, è fatta a pezzi non contigui e sproporzionati. Dovrebbe riflettere che la rana e la mosca hanno sistemi visivi diversi dal nostro e quindi vedono il mondo in modo diverso da noi. Eppure quello che vedono per loro è il mondo. Possiamo dire:"siamo noi a vedere il mondo nel modo giusto e non questi animali inferiori"? Certo, abbiamo anche detto che l'uomo è al centro dell'universo.Infine dovrebbe riflettere sulle illusioni ottiche e tentare di spiegarle.
30 settembre 2010
Mi riprovo a migliorare la rete neuronale MISCHIA. Invece di diminuire le potenze delle caratteristiche poco o mai presenti e eliminarle sotto una certa soglia, col risultato di eliminare anche i particolari minuti io passerei al concetto di persistenza.Lascerei le potenze intatte o le medierei ma terrei conto solo della persistenza nei confronti.
10 novembre 2010
Proseguono i tentativi di migliorare la rete neuronale. L'idea della persistenza in MISCHIA si è rivelata buona. Ora devo utilizzarla in RICON perfezionandolo.
19 novembre 2010
Gli ulteriori tentativi di migliorare la rete neuronale sono andati a vuoto.L'idea della persistenza funziona sia nella rete neuronale che in RICON. RICON mostra difetti nel riconoscere figure sul rotondo D,O,Q,B penso di avere capito la causa di questi errori.
23 novembre 2010
Trovati dei bugs ma anche degli errori concettuali in RICON. Riscrittura della seconda metà del programma RICON.
27 novembre 2010
Ho corretto bugs ma ho anche modificato dettagli del programma RICON grazie ad alcune idee. Il riconoscimento topologico sbaglia pochissimo e con il riconoscimento protosintattico, che ho pure migliorato, non ho più riscontrato errori. Almeno con il riconoscimento delle immagini che ho.
4 dicembre 2010
Sto correggendo il programma DELTA base del riconoscimento protosintattico. Con queste correzioni penso di poter assottigliare ulteriormente il margine di errore. Questo programma fa parte del file T1.bat fra breve penso di poterlo pubblicare.
6 dicembre 2010
Diverse persone hanno riscontrato che i miei programmi non girano su windows vista o versioni successive di windows. In effetti essi sono creati in ambiente DOS. Quindi chi ha sistemi operativi che non supportano il DOS dovrebbe scaricare l'emulatore dal sito http://www.nontipago.it/Sistema/DOSbox.htm
10 dicembre 2010
Mi è stato giustamente consigliato di trasformare i file dal vecchio formato .com a quello .exe. L'idea è buona ma per farlo io dovrei studiare il Borland pascal 7 o il free pascal e tradurre tutto. Non posso. Non ho tempo. Devo dedicarli al riconoscimento sintattico. Se qualcuno è convinto del mio lavoro e vuole aiutarmi renderlo più moderno ed efficiente mi contatti. Per un informatico, un perito o un ingegnere dovrebbe essere semplice. Per me è un impresa titanica.
5 gennaio 2011
Ho provato con il Pascal 7, poi con Lazarus. Ho
solo dovuto lottare con il computer ed ho abbandonato l'impresa. Sono
rimasto alla vecchia versione del pascal. Tuttavia ho completato una
"friendly interface" che dovrebbe essere chiara per chi
vuole provare i programmi.
24 gennaio 2011
Adesso so che cosa significa programmare per oggetti. Ho anche scritto alcuni semplici programmi in Delphi, anzi in Lazarus che è un suo clone. E' stato tempo sprecato. Non userò mai questi linguaggi che, secondo me vanno benissimo per progettare videogiochi, per fare delle belle interfacce ma se uno si prova a svolgere programmi difficili si trova a dover lottare con un mare di istruzioni e perde di vista lo scopo. Per me andavano meglio i vecchi linguaggi di programmazione, con un po' di grafica, che il Fortran non aveva, per cui sono passato al pascal.In qui linguaggi le istruzioni erano in sostanza due if e go to.
18 febbraio 2011
NOTTE, ore 1,30. Quasi per gioco, sto insegnando al computer a leggere il birmano. Impara senza difficoltà con limiti (previsti) del riconoscimento topologico e di memoria del programma in pascal. Senza toccare nulla nel programma imparerà anche il cinese o a riconoscere delle navi o degli aerei.

Fig.22
Mattino, ore 11,30.
Ho svolto ulteriori prove.
Tutto va come previsto.
1. Certe figure sono troppo complesse e
producono un numero di elementi superiori ai limiti degli array del
programma RICON, per esempio le lettere ta e gna.
2. La
mancanza, in questa versione, dell'analisi delle linee interne
impedisce al programma di discriminare fra ka e na, ma anche fra fra
sa,da2 e wa.
3. Il programma discrimina bene fra ga1 e ya ma con
il protosintattico la discriminazione è
inequivocabile.
Ulteriori prove sarebbero, per i fini di
conoscenza che mi propongo, solo una perdita di tempo.
Miglioramenti nella stesura dei programmi aggiustamenti ad hoc invece
permetterebbero di costruire buoni ocr e icr industriali o sistemi
per riconoscere le impronte digitali o navi o aerei. Effettivamente
l'uso del mio programma di riconoscimento è macchinoso, chi
vuole ripetere le mie prove faccia così.
1. Cancelli il
file RICORDI, perché se vi sono lettere dell'alfabeto latino è
ovvio che nga viene confuso con c. Ho in mente come si fa a
meccanizzare i contesti ma non è questo il punto.
2.Stampi
la fig. 23 in modo che sia larga 14 cm, ogni casella che contiene una
lettera deve essere un quadrato di 2,7x2,7 cm.
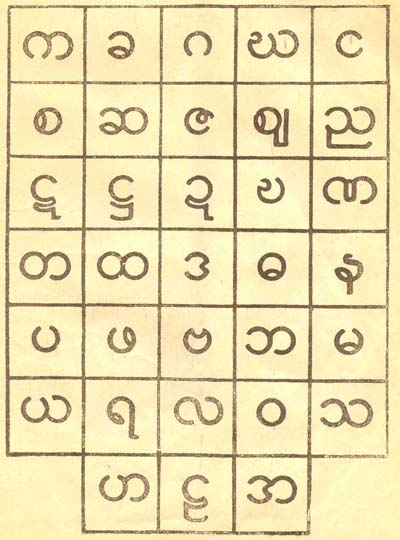
fig.23
3. Ricalchi le lettere con
un pennarello nero.
4. Ritagli un quadrato con le prime quattro
lettere, dico con ka, kha, sa e sha, lo metta sullo scanner e lo
scannerizzi con risoluzione 75 dpi e con l'opzione livelli di grigio,
formato A4. Salvi il file con il nome UNO.bpm, in formato bitmap,
nella cartellina eseguibili e immagini.
5. Trasformi il file da
UNO.BPM in UNO.PIC usando l'applicazione leggi.bpm.
6. Lanci
Guarda.bat, richiami il file UNO e dia il nome ka,kha, sa e sha alle
quattro lettere.
7. Ritagli il quadrato con ga,ga1,za e za1 e
ripeta le operazioni dal punto 4, salvando il file DUE.bpm.
8.
Ritagli il rettangolo che contiene nga e gna e ripeta dal punto 4 al
punto 6 salvando il file TRE.bpm.
ecc... ecc.
9.
Memorizzate tutte le lettere ogni lettere disegni a mano libera una
(o al massimo quattro) di queste, in un quadrato di 2,7x2,7 cm, le
scanerizzi chiami il file PROVA.BPM, lo trasformi in PROVA.PIC
vedrà che il programma la riconosce.
E' interessante
usare il protosintattico per discriminare ya e ga1, fig. 24

fig.24
1
luglio 2011
Ho corretto il programma DELTA vi era un errore materiale che ne abbassava le prestazioni. Ora va molto meglio. Prima di dedicarmi al sintattico voglio ancora migliorare i programmi CONTR e RICON perché creano dei problemi con le forme rotonde, come le lettere O,D,Q.
27 settembre 2011
Ho trascorso l'estate migliorando i programmi di riconoscimento. Ora essi funzionano meglio, non ho però apportato innovazioni concettuali. Sono diventato consapevole che non è più possibile continuare a programmare in pascal sotto dos. I simulatori dos non funzionano benissimo. Uno dei problemi più grossi che i lettori hanno riscontrato sono nella grafica e nel concatenamento dei programmi. Io stesso non sono riuscito a concatenare il programma MISCHIA dal programma OPZIONI, pertanto MISCHIA dovrà essere lanciato manualmente. Tutti questi problemi mi hanno indotto a trascrivere tutto in Lazarus. Quindi per qualche mese quindi sarò preso da questo lavoro.
14 dicembre 2011
Ho terminato la trascrizione dei programmi in Lazarus. Essi ora girano sotto windows. Ora inizierò a lavorare sul riconoscimento sintattico. In una prima fase mi concentrerò sulle forme comprese nella siluette o esterne ad essa. Poi passerò a correggere e ad aggiornare il lavoro che ho già presentato come riconoscimento protosintatico.
26 marzo 2013
26th
March 2013
Ho corretto i programmi. con poche modifiche concettuali. Li ho semplificati. Mi sono interessato solo alla siloutte della figura ed ho trascurato le linee interne, tanto sono trattate allo stesso modo. Ho eliminato delle parti legate all'invarianza della figura per rotazione. Erano pesanti e non aggiungevano nulla di concettuale al programma. Ho perfezionato il riconoscimento protosintattico. Ho eliminato, con l'intenzione di rimetterla entro poche settimane, la rete neuronale detta MISCHIA, che affina le caratteristiche delle forme. Infatti essa richiede troppe forme e un apprendimento troppo lungo, tenterò di ridurre a tre il minimo numero di forme necessarie affinchè estragga le loro caratteristiche. Anche senza MISCHIA il riconoscimento funziona: la macchina riconosce le forme in banca dati, quasi senza sbagliare, partendo dalla forma in posizione (1,1). I rari errori derivano dal riconoscimento sintattico, che richiede la forma affinata da MISCHIA. Il riconoscimento topologico va meglio, in esso la forma giusta ha il numero 'SOMPOT' maggiore. Rare volte il programma abortisce e questo è dovuto al fatto che delle variabili vanno fuori dei limiti consentiti.
I have been correcting the
programs, with some little conceptual modifications. I have been
simplifying them. I have been interested to the siloutte of the
figure and I have neglected the internal lines, because they are
processed in the same way. I have been eliminating all the parts tied
to the invariance of the figure for rotation. They are heavy and they
do not conceptually contribute to the programs. I have been improving
the protosyntactic recognition. I have been eliminating, with this in
mind to put again it in few weeks, the neural network called MISCHIA
that refines the features of the forms. It requires too many forms to
learn. I am trying to reduce to three the shapes necessary for
teaching it. However, even without MISCHIA, the system recognizes the
forms in the data bank, with few mistakes, starting from the figure
in position (1.1). The topological recognition is corrected, you can
see it from the number near the name of the form, few times there are
errors in the protosyntactic recognition, which requires the shapes
refined in MISCHIA but is obvious. Seldom the programs abort and this
is owed to some variables which go out of the allowed limits.
21 aprile 2013
21th April
2013
Migliorate le istruzioni su come acquisire le immagini per accrescere
la banca dati. Continua il miglioramento della rete neuronale.
I
have been improving the instructions in order to scan images
necessary to increase the data bank. The improvement of the neuronal
net continues.
25 luglio 2022
25th July 2022
Sto meccanizzando la grammatica e fra breve pubblicherò i miei studi. Sono giunto al progetto di un dispositivo, già intuito da Chomsky, che permette di generare ogni sorta di grammatica. Tuttavia il problema grosso non è la grammatica ma la pragmatica che, a mio avviso, richiede il contatto diretto della macchina con l’ambiente, attraverso il senso della vista. Saprei come fare ma non ho le capacità tecniche per costruire tale apparato. Spero che qualcuno mi aiuti. Vedo che le pagine del mio sito sono lette molto spesso a Boardman negli USA e a Putian in Cina sarei lieto di collaborare con queste persone. Capisco le potenzialità economiche dei miei studi, tuttavia io non li svolgo con tali intenti ma per puro interesse scientifico.
I have been mechanizing grammar, and I’m publishing my studies soon. I have designed a device, already intuited by Chomsky, that allows you to generate all sorts of grammar. However the big problem is notthe grammar but the pragmatic that, in my opinion, requires the direct contact of the machine with the environment through the sense of sight. I would know as do but don’t have the technical skills to build suchan apparatus. Would someone help me? I see that the pages of my site are read very often to Boardman in the USA and to Putian in China I would be happy to collaborate with these readers. I understand the economic potential of my studies, even if I have not done them with such intentions but out of pure scientific interest.
19 dicembre 2022
Queste sono le basi su cui incardino lo studio che sto svolgendo sulla meccanizzazione della grammatica. In esso tratto di un dispositivo che permette di passare dalla grammatica di una lingua a quella di un’altra. Sto finendo il lavoro, per ora l’ho scritto in italiano. Appena esso sarà pronto lo tradurrò in inglese.
These are the foundations on which I embody the study I am carrying out on the mechanization of grammar. In it I draw a device that allows you to pass from the grammar of one language to that of another. I am finishing the work, for now I have written it in Italian. As soon as it is ready I will translate it into English.
Link: La meccanizzazione della grammatica.pdf